教程:SQL Server 2008 数据挖掘的概念(4)
您必须了解数据,以便在创建挖掘模型时作出正确的决策。浏览技术包括计算最小值和最大值,计算平均偏差和标准偏差,以及查看数据的分布。例如,通过查看最大值、最小值和平均值,您可以确定数据并不能代表客户或业务流程,因此您必须获取更多均衡数据或查看您的预期结果所依据的假定。标准偏差和其他分发值可以提供有关结果的稳定性和准确性的有用信息。大型标准偏差可以指示添加更多数据可以帮助改进模型。与标准分发偏差很大的数据可能已被扭曲,抑或准确反映了现实问题,但很难使模型适合数据。
借助您自己对业务问题的理解来浏览数据,您可以确定数据集是否包含缺陷数据,随后您可以设计用于解决该问题的策略或者更深入地理解业务的典型行为。
BI Development Studio 中的数据源视图设计器包含数种可用于浏览数据的工具。
此外,在创建模型时,Analysis Services 还会针对该模型中包含的数据自动创建统计摘要,您可以进行查询以便用于报告或进一步分析。
生成模型
如以下关系图中突出显示的那样,数据挖掘过程的第四步就是生成一个或多个挖掘模型。您将使用从浏览数据步骤中获得的知识来帮助定义和创建模型。
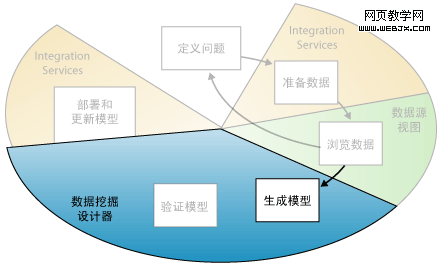
通过创建挖掘结构定义要使用的数据。挖掘结构定义数据源,但只有对挖掘结构进行处理后,该结构才会包含任何数据。处理挖掘结构时,Analysis Services 生成可用于分析的聚合信息以及其他统计信息。基于该结构的所有挖掘模型均可使用该信息。
在处理模型之前,数据挖掘模型只是一个容器,指定用于输入的列、要预测的属性以及指示算法如何处理数据的参数。处理模型也称为“定型”。定型表示向结构中的数据应用特定数学算法以便提取模式的过程。在定型过程中找到的模式取决于选择的定型数据、所选算法以及如何配置该算法。SQL Server 2008 包含多种不同算法,每种算法都适合不同的任务类型,并且每种算法都创建不同的模型类型。
此外,还可以使用参数调整每种算法,并向定型数据应用筛选器,以便仅使用数据子集,进而创建不同结果。在通过模型传递数据之后,即可查询挖掘模型对象包含的摘要和模式,并将其用于预测。
您可以在 BI Development Studio 中使用数据挖掘向导或使用数据挖掘扩展插件 (DMX) 语言来定义新的模型。
务必记住,只要数据发生更改,必须更新数据挖掘结构和挖掘模型。重新处理挖掘结构以进行更新时,Analysis Services 检索源中的数据,包括任何新数据(如果动态更新源),并重新填充挖掘结构。如果您具有基于结构的模型,则可以选择更新基于该结构的模型,这表示可以根据新数据保留模型,或者也可以使模型保持原样。