robots.txt文件规则是否正确:测试robots.txt规则反应
10月20日,我对博客进行了大规模调整,就如同对待亟待成长的树一般修枝剪叶,以期能有较好的成长趋势。其中robots.txt被我充分的利用起来。
如今一个工作周即将过去,robots.txt文件规则是否正确,是否已经生效?百度谷歌等搜素引擎是否响应了robots.txt规则进行索引调整?作为站长我需要深入研究一番,以便动态掌握博客收录状态。
经调查发现,谷歌对robots.txt反应比较迅速,第三天在网站管理工具里找到了迹象。百度表现不尽如人意,说百度不认robots.txt规则那是瞎扯,但反应周期如此之长,难免会留下反应慢不作为的猜疑。
看谷歌对robots.txt规则之反应
在20日做的调整中,有两条规则我后来做了删除。打开我博客的robots.txt,和20日进行调整写下的对比,可知其中变化。
作此调整的原因在于,如按照20日的写法,第二天我发现,网站管理员工具Sitemaps里三个被选中的地址前出现了叉号——被robots.txt文件规则给阻止了——这个没必要嘛。当时的截图找不到了,下面三个选中的可以看一下:
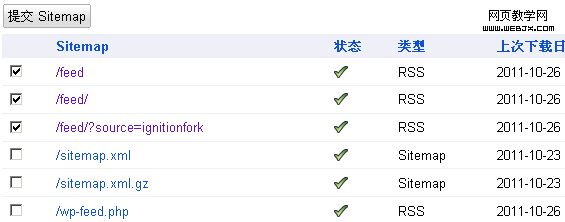
提交的sitemap网站地图
响应robots.txt规则,谷歌停止了2000 多个连接地址的抓取。那500多个找不到地址,是因为前段时间删除文章标签tags后遗症。下面是截图:

2000多个连接地址被robots.txt规则限制
翻遍每一页,没有发现问题——除了一些/?p=的短连接让人心疼外,一切完美无暇。严格来说,应该是robots.txt规则不存在问题,谷歌不折不扣的执行了robots.txt规则。
谷歌查询“site:***.com inurl:?p” 仅找到残缺的14条(无标题或摘要)。不久的将来这些地址将被清除。
看百度对robots.txt规则之反应
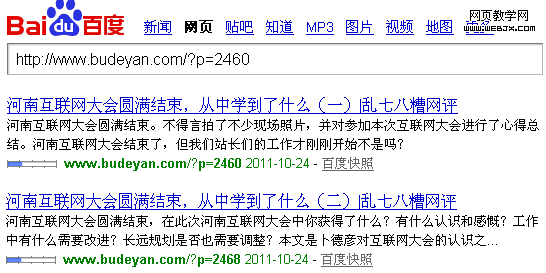
20日就有robots.txt文件规则了,这是什么情况?
规则20日制定,上面这图不知是穿越了,还是我眼花了?我查过IIS日志记录,百度20日后曾多次下载robot.txt文件,服务器返回的是200成功状态码。
难怪百度不招各位站长待见。
百度“亲爱的站长,我是你爹”高高在上的态度,是否应该转变一下了?
原文地址:不得言博客