�Ӽ����ǶȽ�����վ����δ�С�ɳ�����(2)
�����û���session�����ͬ����That’s a good question��TOO��
��ȻHTTPЭ����һ����״̬�ķ���Э�飬���ǣ��û��Ļ�����Ϣ��Ҫ���ܹ���֤�ġ����磺��¼��Ϣ��ԭ���ڵ�����ʱ�����ǿ��Ժܼ�ʹ������setSession��“user”�� ”XXX”���ĺ������������ʹ�ö����ʱ����ô��������أ�
��ʵ�������Ҳ�ǵ��������Һܾõ�һ�����⡣�����setSession���û���ijһ̨�����ϵ�¼�ˣ����´���������ʱ�����������ˣ��ͱ��δ��¼�ˡ�Oh��My God��
Ok��������һ������������
1��һ̨������¼������������֪����
2���û�������ܵ���̨������
���ڵ�һ�����⣬���������һ̨�����ĵ�¼��Ϣ����������֪��������OK������ߣ���Ҷ���һ̨�����ϵ�¼�����Ϳ������ ���ڵڶ������⣬���������ͬһ���û�������ֻ����ͬһ̨�����ϣ�����OK�����ˣ����ǿ���������ֽ��������
1���ṩsessionͬ�����ƣ�
2���ṩͳһsession����
3����ͬһ�û�������ͬһ������
�ţ������ַ�ʽ�����ѡ�ĸ��أ�������ң��Ҿ�ѡ���һ������Ϊ����һ�����棬�һ�ѡ���һ�������ŷ��һ��ԭ����ǣ��ֱ���Ч����������WebServer��ʹ��һ��Hash�㷨����session_id���з��������WebServerû���ṩ�ù��ܣ����Լ�дһ����չ�����߸ɴ���WebServer������һ���������ɣ����������ַ�����һ�����������⣬��һ̨����崻����Ժû����ϵ������û���session��Ϣ���ᶪʧ����ʹ�����˴��̱��ݣ�Ҳ����һ��ʱ�����sessionʧЧ��
�ã��ǿ�����һ�ַ�������ʵ������һЩ����Ѿ��ṩ�������ķ�����ơ�����Tomcat���ṩsessionͬ�����ơ��������е�Э�飬��һ̨�����ϵ�session����ͬ���������Ļ����ϡ���������һ�����⣬����Ҫ�����еĻ�����������Ҫͬ���Ļ�������������϶�˲��������ˣ����������ң����session���Ƚϴ�Ļ���ͬ����ʵЧ�Ի���һ�����⡣
�����������ڶ��ַ������ṩͳһsession����������ǵ�����дһ��������������session���������������ķ�ʽ�ṩ��ѯ���¡�����������һ���εķ����������Ե�����һЩ����Ϊ������������������ֻ�����һ�����������⣬���磺��������Ƿ���ڵ��㣨һ̨�����������崻������ֹͣ����ʹ��ʲô����Э�������н����ȵȡ���Щ��������������ζ����ò�����������ԣ��������������Ҳ���Ǻ�������
�ðɣ����ַ���ѡ��һ��������㣬���ѡ��һ���أ������и��õķ����������ûǮûʵ������˵�е�“��˿”�����������ҾͿ�������һ�·�����ȶ��ԣ����ô�����͵ġ�
�������ݷ���ͬ�����⡣
���������ͬʱ������Ҿ���ͬһ��Դ��ʱ���磺��ɱ�����Ƕ���Ʊ����������ô������أ�
���ʱ����Ϊ�����õ����������ݿ⣬���Ժܺõ��������ݿ��“��”���������������⡣һ������ݿⶼ�ṩ����Ĺ��ܡ�����ļ���ֶ��֣�������ظ��������л��ȣ����ݲ�ͬ��ҵ�������ܻ�ѡ��ͬ���������ǿ�������Ҫ��������Դ�ϼ�����������ͬ����Դ�������ǣ��������Ҳ�������ܵģ����Ἣ���Ӱ��Ч�ʣ����Ծ����ļ�������ʹ�ã������Ѿ�ʹ�����ĵط��������Ż���������Ƿ���ܳ���������
cacheҲ�ж�Ӧ�Ľ�������������ӳ�ɾ�����߶���ʱ��ȼ�������������Դ��һ��ʱ�䴦�ڲ��ɶ�״̬���û�ֱ�Ӵ����ݿ��ѯ��������֤���ݵ���Ч�ԡ�
���ˣ������������⣬Ӧ�ú���������������������Ĵ����⡣��ô���������ڿ�������ļܹ�ͼ������������
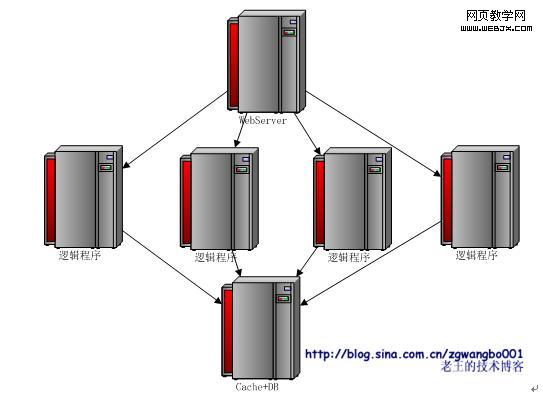
���Ľṹ���㹻���dz�һ��ʱ���ˣ�������Ϊ���������״̬�ԣ�����ͨ�����ӻ�������չ��������������Ҫ��Եģ������ύ�����Ͳ�ѯ�����Ӵ����Ĵ洢���ܵ�ƿ����
�������Σ�д���룬����IO���ܡ�
���ˣ�����������Σ����ǵĵ������ݿ�����Ѿ���Ϊƿ�������ݿ���ֱȽ����صĶ�д��ͻ����������̻߳������Ϊ��д��Ҫ���������̣�ʹ�ô��̵Ĵ�ͷ���ϱ任�ŵ�����Ƭ����ɶ�д���ܻ�������
������������������⣬��������Щ�����������
һ�����ٶ�ȡ�����������е�������Դ������Ϊ��д�����ӣ����Կ������������ֱ�����Դ�Ľ���취���������û�����ô��������������ô���ܼ����أ���ʵ������Խ��˵�ϵͳ������Խ���ܵ����顣���ǿ�����ÿһ�㶼����һ����������������嵽���ݿ�Ļ������ǿ��Կ���ͨ������cache�����ʣ��������ݿ�ѹ��������cache�������кܶ��з����������ҵ�����ģʽ�����Ż����༶cacheģʽ�������ڴ������ȵȡ�ҵ��ģʽ���IJ���̫��ͨ�ã�����������ǿ������ͨ�������ڴ�������������⡣
���ڵ���������ͨ�õ�cache����һ�㶼���������ڴ��С�����ֻ��Ҫ�ܼ����ü��ɡ����⣬����Ҳ���Կ��Ƕ��cache�ķ�����ͨ�����ӻ����������ڴ���������ˣ����Ǿ������˷ֲ�ʽcache�����ڳ��õ�cache���磺memcache���������������Ĺ��ܣ�֧�ֶ��cache������ͨ�����ؾ����㷨���������ɢ����̨��ͬ�Ļ����ϣ��Ӷ������ڴ�������
����Ҫǿ��һ�㡣������ѡ������㷨��ʱ�����п��ǵġ����ʱ����ѡ��һ��Hash�㷨����ijһϵ��ID���䵽�̶��Ļ����������Ļ����ܷŵ�KV�Ի����������л�����ӡ�����������������ķ��䣬���л����ڴ���������ݻ��д����ظ����ڴ沢û�кܺõ����á����⣬��Ϊ����һ��Hash����ʹһ̨����崵���Ҳ��ȽϾ��ȵķ�ɢ�������������������˲����������cache����ʧЧ�����е����⡣
��������д������Ҫ�����û����ύ������������Dz�̫��ʵ�ġ�ȷʵ������Ҫ����д������ƺ��Ǻ��ѵ�һ���¡�����Ҳ������ȫ�����ܡ��������ǻ��ᵽһ��˼�룺�ϲ�д�롣���ǽ��п��ܵ�д�����ڴ�����кϲ�����һ��ʱ�����һ����������һ��д�롣��ʵ����mysql�ȴ洢�����ڲ��������������Ļ��Ƶġ�����ȷ���������һ���������û�������Ʒ��������ÿ���û�������Ʒ��������һ������������ڲ���ÿ�ζ�ȥʵʱд���̣����ǵ�һ����ʱ���һ����������д�룬�����Ϳ��Լ��ٴ�����д����������ǣ�������Ҫ���ǣ����������崵��Ժ��ڴ����ݵĻָ����⣨��һ���ֻ��ں���������������ˣ�������ʹ�����ݺϲ�����������������Ҫ�Բ��Ǻ�ǿ��ҵ��ʹ����һ�������ݣ�Ҳû�й�ϵ��