从技术角度讲解网站是如何从小成长起来(3)
三、多机承担请求,分散压力。如果我们能将原来单机的服务,扩充成多机,这样我们就能很好的将处理能力在一定限度内很好的扩展。那怎么来做呢?其实有多种方法,我们常用的有数据同步和数据订阅。
数据同步,我们将所有的更新数据发送到一台固定的数据服务器上,由数据服务程序处理后,通过日志等方式,同步到其他机器的数据服务程序上。如下图:
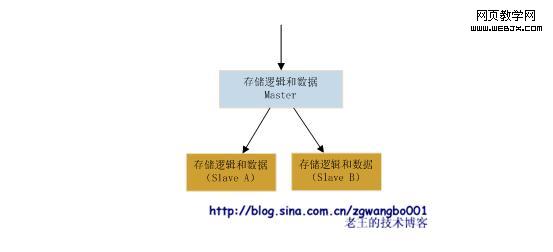
这种结构的好处就是,我们的数据基本能保证最终一致性(即:数据可能在短暂时间内出现不一致,但最后的数据能达到一致),而且结构比较简单,扩展性较好。另外,如果我们需要实时数据,我们可以通过查询Master就行。但是,问题也比较明显,如果负责处理和分发的机器挂掉了,我们就需要考虑单点备份和切换方案。
数据订阅,我们也可以通过这样的方式来解决数据多机更新的问题。这种模式既是在存储逻辑和数据系统前,增加一个叫做Message Queue(消息队列,简称MQ)的东东,前端业务逻辑将数据直接提交到MQ,MQ将数据做排队等操作,各个存储系统订阅自己想要的数据,然后让MQ推送或自己拉取需要的数据。
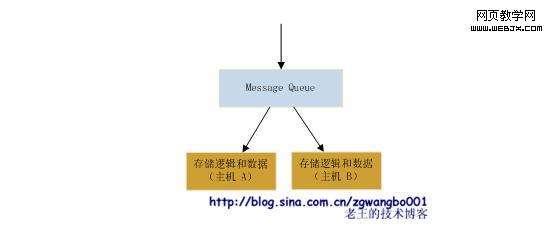
MQ不带任何业务处理逻辑,他的作用就是数据转发,将数据转发给需要的系统。其他系统拿到数据后,自行处理。
这样的结构,好处是扩展比较方便,数据分发效率很高。但是问题也比较明显,因为处理逻辑分散在各个机器,所以数据的一致性难以得到保证。另外,因为这种模式看起来就是一个异步提交的模式,如果想得到同步的更新结果,要做很多附加的工作,成本很高且耦合度很大。还有,需要考虑MQ的单点备份和切换问题。
因为现在数据库(如Mysql)基本带有数据同步功能,因此我们在这个阶段比较推荐数据同步的方法。至于第二种方式,其实是很好的一种思想,后续我们会有着重的提及。那再来看我们的架构,就应该演变成这样的结构。
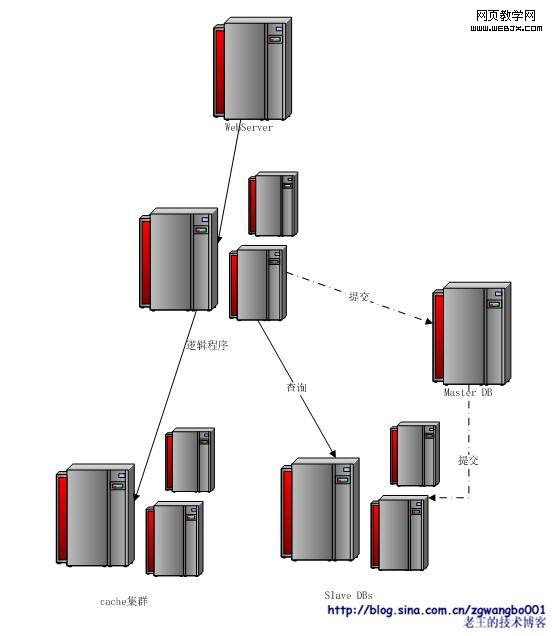
到目前这个阶段,我们基本上就实现了从单机到多机的转变。数据的多机化,必然带来的问题:一致性!这个是否有解决方案?这个时候我们需要引入一个著名的理论:CAP原理。
CAP原理包含了三个要素:一致性(Consistency)、可用性(Availability)、分区容忍性(Partition tolerance)。三个要素中,最多只能保证两个要素同时满足,不能三者兼顾。架构设计时,要根据业务需要进行取舍。比如,我们为了保证可用性和分区容忍性,可能会舍去一致性。
我们将数据分成多机,提高了系统的可用性,因此,一致性的保证很难做到强一致性。有可能做到最终一致性。这也是分布式引入以后的烦恼。
这样的一个系统,也是后续我们分布式架构的一个雏形,虽然比较粗糙,但是他还是比较简单实用,对于一般中型网站,已经能很好的解决问题。
【第七阶段:拆分】
到上面一个阶段,我们初步接触到了逻辑、存储等的多机模式。这样的结构,对于逻辑不是特别复杂的网站,足以撑起千万级的压力。所以大多数网站,只要能够用好上面的结构就可以很好的应对服务压力了。只不过还有很多细节的工作需要精细化,比如:多机的运维、稳定性的监控、日志的管理、请求的分析与挖掘等。
如果流量持续增长,或者是业务持续的扩展,上述的架构可能又将面临挑战。比如,多人开发常常出现版本冲突;对于数据库的更新量变大;一个表里面的记录数已经超过千万甚至过亿等等。
怎么解决呢?还记得我们之前介绍过一个CAP理论嘛?三要素里面有一个东东叫:分区容忍性(Partition tolerance)。其实,这个就是我们接下来解决问题的基础:切分!
一、从数据流向来看,切分包括:请求的切分、逻辑的切分、数据的切分。
数据的切分:将不同的数据放到不同的库中,将原来的单一的一个库,切分成多个库。
逻辑的切分:将不同的业务逻辑拆分成多份代码,用不同的代码管理路径来管理(如svn目录)。
请求的切分:将不同的逻辑请求分流到不同的机器上。比如:图片请求、视频请求、注册请求等。
二、从数据组织来看,切分包括:水平切分、垂直切分。
数据库的变大通常是朝着两个方向来进行的,一个是功能增加,导致表结构横向扩展;一个是提交数据持续增多,导致数据库表里的数据量持续纵向增加。
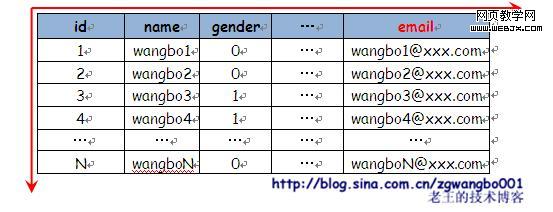
数据量变大以后,单机性能会下降很明显,因此我们需要在合适的时候对数据进行切分(这个我没有太深入的研究过相关数据库的最合适的切分点,只是从经验上来讲,单表的字段数控制在20个以内,记录数控制在5千万以内会比较好些)。
垂直切分和水平切分,其实是挺纠结的两个词。我之前对这两个词经常搞混。后来自己画了个图,就很直接明了了。
水平切分:
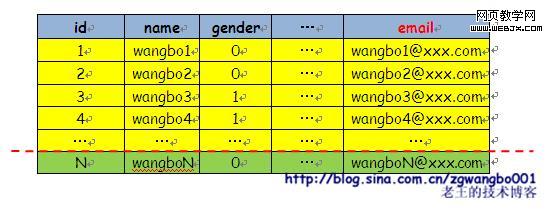
水平切分就是因为记录数太多了,需要横着来一刀,将原来一张表里面的数据存入到多张表中,用于减少单张表里的数据量。
垂直切分:
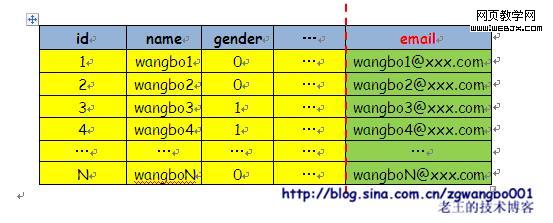
垂直切分就是因为业务逻辑需要的字段太多,需要竖着来一刀,将原来放在一张表里的所有字段,拆分成多张表,通过某一个Key来做关联(如关系数据库中的外键),从而避免大表的产生。