从技术角度讲解网站是如何从小成长起来(6)
【阶段性小结】
经过了上述的架构扩展和优化以后,我们的系统无论是从前端接入,还是后端存储都较最初的阶段有了质的变化。这样的架构足以支撑起10亿级别的流量和10亿级别的数据量。我们具体的来看一下整体的架构。
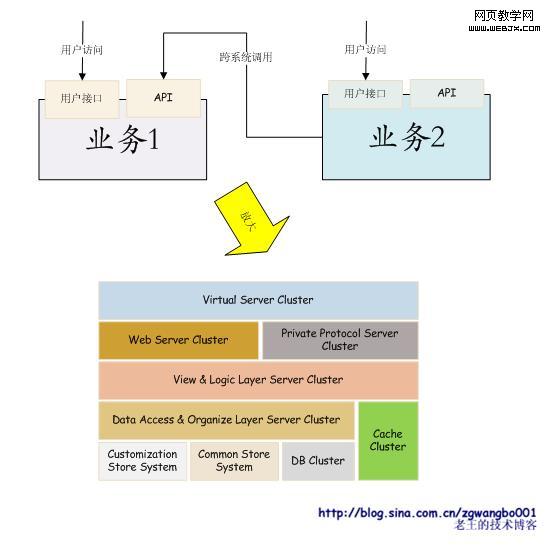
上述的模型是我个人觉得的一个比较理想的模型。Virtual Server Cluster接收数据包,转发给Web Server Cluster或者Private Protocol Server Cluster(如果有的话)。然后视图和逻辑层server负责调用cache或者数据访问组织层的接口,返回处理后的数据。定制存储系统、通用存储系统和数据库集群,提供基本的数据。
每一个层次通过负载均衡和一定的协议来获取下一层提供的数据,或者提交数据。在存储系统内部,通过Meta信息管理、主从同步、消息订阅等方式,实现数据的同步。
如果我们再要扩大规模,比如:机器数扩展到上千台、万台。对于我们来说,管理机器就成为了机器头等的大问题。
同时,我们之前还有几个问题没有很详尽的描述,比如:数据传输协议、远程系统调用、系统的异构性等等,这些都是会影响到我们系统可维护性的大问题。
我7年前就开始使用Java,到现在,总算能看懂一些东西了。J2EE我个人觉得确实是一个比较伟大的东东。里面其实早已经提出了一套比较完善的解决大型或者超大型网站的整体解决方案。
比如:
1、JNDI(Java Naming and Directory Interface):描述了如何使用命名和目录等的规范,使得我们能够将服务作为资源挂接到命名服务器上,并且通过标准的接口进行访问。这对我们管理巨大的机器资源和服务提供了很好的方案。
2、RMI(Remote Method Invoke):远程过程调用。即,通过标准的RMI接口,可以轻松实现跨系统的远程调用。
3、IDL(Interface Definition Language):接口定义语言。这个本来是CORBA中用来访问异构系统对象的统一语言,其实也给我们提供了跨系统调用中,对外接口的定义方案。
4、JDBC(Java Database Connectivity):数据库访问接口。屏蔽了不同数据库访问的实现细节,使得数据库开发变得轻松。
5、JSP(Java Server Page):实现将视图和控制层很好分离的方式。
6、JMS(Java Message Service):用于和面向消息的中间件相互通信的应用程序接口。提供了很好的消息推送和订阅的机制。
以上这些组件其实很好的协助构建了J2EE整体架构。我的很多想法都来源于这些东东。后续会结合这些,详细来分析诸如资源命名位置服务、数据传输协议、异构系统接口定义等解决大规模机器运维问题的方案。
【第十一阶段:命名位置服务】
在前面我们不止一次提到了命名位置服务(Naming & Location Service)。在不同的架构或者公司里面,这个名字往往不一样,比如,在java里面叫JNDI(Java Naming & Directory Interface),在有些地方可能会叫做资源位置系统(Resource Location System)。
总之,不管叫什么名字,我们要知道的就是为什么要有这样的系统?他能做哪些事情?他有哪些实现方式?等等。
在我们之前的章节中,我们的服务从一台单机扩展到十台左右的多机,到成百上千台机器。我们的服务从单一的一个服务扩展到成百上千的服务。这么多的机器、服务,如果不好好管理,我们就崩溃了。比如,我们的服务A要连接服务B,如果现在采用配置IP的方式,可能需要配置几十台机器的IP,如果其中某些机器出现了变更,那所有服务A连接服务B的IP都要改变。如果所有的服务都是这样,这将是多么痛苦的一件事情 Orz。
如果我们只是简单的将我们的服务看成是一个个的资源(Resource),这些资源可以是数据库,可以是cache,可以是我们自己写的服务。他们都有一个共同的特点,就是在某一个IP上,打开一个PORT,遵循一定的协议,提供服务。
我们先简单的来构建这样一个模型。我们这里先抽象一个接口,叫做Interface Resource。这个接口下面有多个实现,比如:DBResource、CacheResource、ImageResource等等。具体类图如下:
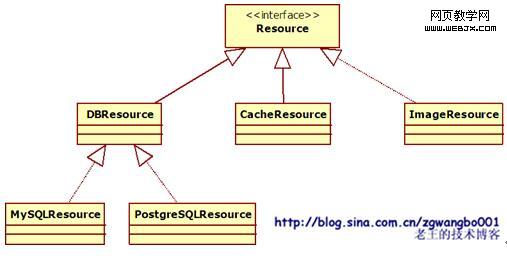
有了这样的一个层次结构以后,我们为了得到某一个实例,有多种方式,比如:
1、直接生成的方式:
Resource r = new ImageResource();
2、间接生成的方式:
A、比如我们在设计模式中经常使用到的工厂模式:
Resource r = ResourceFactory.get("Image");
B、IoC(Inversion of Control)方式:
Resource r = (Resource)Container.getInstance("ImageResource");
我们打一个不是很完全匹配的比方。我们如果直接在服务中采用IP配置的方式,就类似于直接生成实例一样,如果实例发生变化,或者要调整生成的对象,就需要修改调用者的代码。也就是说,如果其他服务的IP发生变化,我们调用者就需要修改配置,重启程序等等。而且对于如果有很多很多这样的服务,我们就崩溃了。
那么,我们觉得更好的一种方式呢,就是,如果有一个工厂,或者一个容器,来帮我们管理这一堆的服务IP、端口、协议等等,我们要用的时候,就只需要叫一声:“给我XXX服务的实例”,那是多么美妙的事情啊!
其实呢,我们的命名位置服务要做的就是这样的事情。他类似于一个Meta Server,记录所有服务的IP、port、protocol等基础信息,以及检查这些服务的健康状态,提供给调用者最基础的信息服务。同时,再结合调用时的负载均衡策略,就可以帮我们提供很好的资源管理方式。
这个服务,提供注册、注销、获取列表等接口。他的存在,就将直接关联的两个服务给很好的解耦了。我们看看对比:
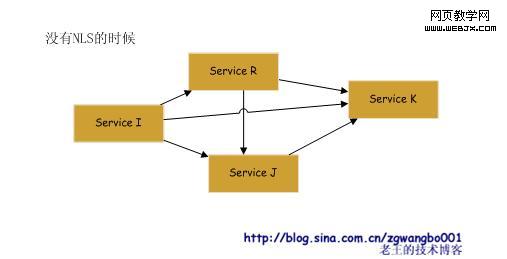
在没有Naming Location Service的时候,我们的服务相互直接依赖,到最后,关联关系及其复杂,可能完全没有办法维护。
如果我们增加Naming Location Service以后,这个状态就可以得到极大的改善。

这个时候,我们所有的服务都在NLS上注册,同时向NLS获取其他服务的信息,所有的信息都汇聚到NLS上管理。
有了这个服务,就好类比成我们生成一个类的时候,采用间接的方式生成。
Service s = (Service) NamingService.getService("Image");
好,有了这样一个架构以后,我们可能会关注这个NLS如何来实现。
实现这个服务有简单的方式,也有复杂的方式。关键是要考虑以下几个方面:
1、如何找到这个NLS。NLS是所有服务的入口,他应该是有一个不变的地址来保证我们的服务。因此,我们可以使用我们之前提到过的Virtual Server的方案,通过一个(或多个)固定的域名或者IP来绑定这个服务。
2、可用性(Availability)和数据一致性(Consistency)。因为这个服务是一个最基础的服务,如果这个服务挂掉了,其他服务就没有办法来定位了。那么这个服务的稳定和可靠性就是及其重要的。解决方案有如下几种:
A、单机实现服务,本地增加备份。我们用单机来实现这样一个服务,这样可以保证绝对的数据一致性。同时,每次请求数据后,每个服务本地保留一份备份数据。当这个服务挂掉了,就使用最近的一次备份。这个方案对于大多数情况是足以应付的,而且具备简单粗暴有效的特点。
B、多机服务,数据同步。采用多机提供服务,信息更新时进行数据同步。这种方式的优点就是服务可以保证7*24小时服务,服务稳定性高。但是,问题就是维护成败会比上面一种方式高。
3、功能。实现服务名称到IP、Port、Protocol等信息的一个对应。如果要设计的更通用,比如可以注册任何信息,就只需要实现Key-Value的通用数据格式。其中,Value部分需要支持更多更丰富的结构,比如List、Set等。
有了这样的一个系统,我们就可以很方便的扩展我们的服务,并且能很好的规范我们服务的获取、访问接口。