从技术角度讲解网站是如何从小成长起来(4)
好了,有了上述的基础以后,我们再来看实际问题如何来解决。
假设,现在我们有一个博客网站,这个网站拥有多个功能,如:图片、博客、用户信息等的插查删改操作。而现在博客数据膨胀比较厉害。
首先,我们从数据流向来看,用户访问博客、图片、用户信息等这几个逻辑没有直接的耦合,对应的业务逻辑关联也很少。
因此,我们第一步从入口上就可以把三者分开。最简单的方式就是通过域名来切分,比如:img.XXX.com、blog.XXX.com、user.XXX.com。然后通过不同的WebServer来接收这些请求。
第二步,我们的业务逻辑代码,很明显可以将这些逻辑分开(从部署上分开)。一部分专门处理图片的请求,如ImageUploadAction/ImageDisplayAction/ImageDeleteAction,一部分专门处理博客请求,如:BlogDisplayAction/BlogDeleteAction,一部分专门处理用户相关请求,如:UserModifyAction/UserDisplayAction等等。
第三步,从数据库存储上,将三者剥离开。简单的就是分成三个不同的库。
这样,从数据流向上,我们就按不同的功能,将请求进行了拆分。
其次,从数据存储上来看,由于博客数据量增长比较快,我们可以将博客的数据进行水平的拆分。拆分方法很多,比如常用的:
1、按区间拆分。假定我们用blog_id作为Key,那么我们可以每1千万,做一次切分。比如[1,1kw)、[1kw,2kw)等等。这样做的好处就是可以不断的增长。但访问可能会因为博客新旧的原因,集中到最新的几个库或表中。另外,要根据数据的增长动态的建表。
2、按取模拆分。比如我们预估我们的blog_id最多不超过10亿,如果每张表里面我们预估存入1千万的数据,那么我们就需要100张表(或库)。我们就可以按照blog_id % 100 这样来做切分。这样做的好处是简单,表在一开始就全部建立好了。且每个表或者库的访问都比较均匀。但问题就是,如果数据持续扩张,超出预期,那么扩展性就成为最主要的问题。
3、其他还有一些衍生的方式,比如按Hash值切分等等,大多大同小异。
这样一来,我们通过访问模式、数据组织等多个维度的拆分以后,我们单机能够提供服务的能力就变的比较强悍了。具体的架构如下图。

上述结构看似比较完美,但是在实际的使用中可能会遇到以下几个问题:
1、业务关联问题。多个Service之间不可能没有任何关联,如果出现关联,怎么办?特别是如果是提交的信息要修改多个业务的数据的时候,这个会比较头疼。
2、服务运维问题。这样拆分以后,随着机器数量的膨胀,对于机器的管理将会变的愈发的困难。这个问题直接会影响到整体架构的设计。面向运维的设计是架构设计中必须要考虑的重要因素。
3、还有一个问题是我们WebServer始终是单机的,如果出现宕机等问题,那影响将是致命的。这个我们还没有解决。
这些问题都会在接下来的部分详细来解决。
【第八阶段:WebServer多机化】
上面说了这么多,我们的业务都基本上运转在只有一个WebServer的条件下。如果出现宕机,所有服务就停掉了;如果压力大了,单机不能承载了,怎么办?
说到这个话题,我们需要来回顾一下在大学时学习的关于网络的基本知识。^_^
抛开复杂的网络,我们简化我们的模型。我们的电脑通过光纤直接连入互联网。当我们在浏览器地址栏里面输入http://www.XXX.com时,到我们的浏览器展现出页面为止,中间出现了怎么样的数据变化?(注意:为了不那么麻烦,我简化了很多东西,比如:NAT、CDN、数据包切片、TCP超时重传等等)
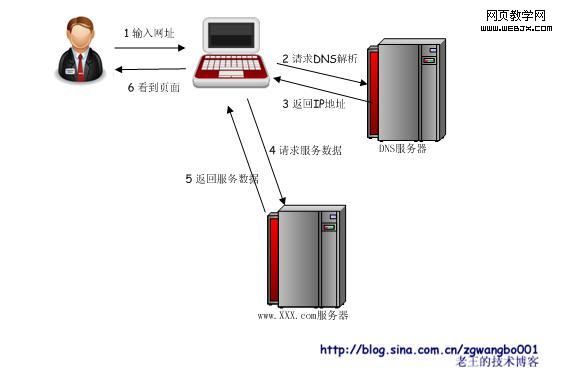
上面的图我们应该比较熟悉,同时也应该比较清晰的表达了我们简化后,从输入网址到页面展现的一个过程。中间有两个东西我们比较关注,也是解决我们WebServer多机化的关键。
1、DNS服务是否能帮我们解决多机化?
2、www.XXX.com服务器的WebServer如何多机化?
首先,如果DNS解析能够根据我们的请求来区分,对于同一域名,将不同的用户请求,绑定到不同的ip上,这样,我们就(友情提示:word统计此处已经达到10000字)能部署多个WebServer,对应不同的ip,剩下的无非就是多申请几个ip地址而已。
当我们网站比较小的时候,我们都是在代理商处购买域名并由代理商的服务域名解析服务器帮我们做域名解析。但是,对于许多大型的网站,都需要对类似于www.XXX.com、blog.XXX.com、img.XXX.com等在XXX.com根下的所有服务的进行域名解析,这样便于对服务进行控制和管理。而域名的解析往往有专门的策略来处理,比如根据IP地域、根据不同请求IP的运营商等返回不同的服务器IP地址。(大家可能以前也有过这样的经验:在不同的地方,ping几个大的网站,看到的ip是不一样的)。
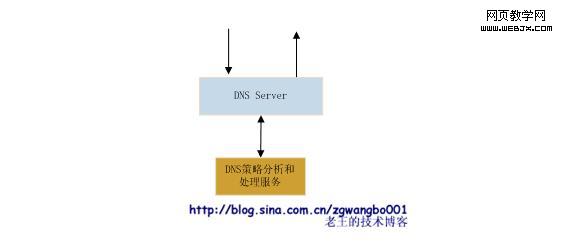
DNS策略分析和处理服务是对请求IP进行分析和判断的系统,判断请求来自哪个地域、哪个运营商,然后根据内部的一些库的判断,决定应该返回哪个WebServer的IP。这样,就能尽量保证用户以最快的速度访问到对应的服务。
但是,如果我们有大量的WebServer,那每个Server都要有一个IP,另外,我们要增加一个新机器,又要申请一个IP地址,好像很麻烦,且不可接受。怎么办呢?
第二点,我们需要考虑对于服务器的WebServer的多机化方式。
我们为什么要WebServer多机化?原因就是因为单机的处理性能不行了,我们要提升处理能力。
那WebServer要做哪些事情?Hold住大量用户请求连接;根据URL将请求分流到不同逻辑处理的服务器上;有可能还有一些防攻击策略等。其实这些都是消耗CPU的。
如果我们在WebServer前端增加一层,什么逻辑都不处理,就是利用一定的负载均衡策略将数据包转发给WebServer(比如:工作在IP层,而非TCP层)。那这一层的处理能力跟WebServer比是否是要强悍很多?!这样的话,这一层后面就可以挂载很多的WebServer,而无需增加外网IP。我们暂且叫这一层叫VS(Virtual Server)。这一层服务要求稳定性较高,且处理逻辑要极为简单,同时最好工作在网络模型中较低的层次上。
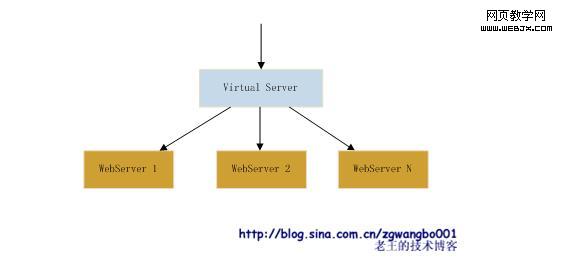
这样的话,我们就只需要几个这样的VS服务器组,就可以组建大量的WebServer集群。当一个群组出现问题,直接可以通过改变IP绑定,就可以切换到其他服务器组上。
现在这样的VS实现有多种。有靠硬件方式实现的,也有靠软件方式实现的。硬件方式实现的话,成本较高,但稳定性和效率较好。软件方式实现的,则成本较低,但稳定性和效率较硬件方式要低一些。
现在用的比较多的有开源的LVS(Linux Virtual Server),是由我国的一个博士写的,NB!以及根据LVS改写后的一些变种。
另外还有F5 Networks公司出的收费的F5-BIG-IP-GTM等。(注:这个确实没用过,以前在网上看过,写到此处记不清,在百度上搜的。如有错误,敬请雅正)。
好了,通过上述的方式,我们基本实现了WebServer的多机化。
【第九阶段:逻辑关联和层次划分】
在第七阶段的时候,我们提到了几个问题,其中有一个就是业务关联问题。当我们将业务拆分以后,多个业务之间没有了耦合(或者是极弱的耦合),能够独立的运转。这个看起来是多么美妙的事情。但是实际情况真是如此嘛?
这样的业务还真是存在的。比如我们有两个业务blog和image。blog可以上传和展示图片。那image.XXX.com就提供两个HTTP服务,一个是上传的,一个是显示的。这样,blog业务就可以通过简单的URL耦合来实现了图片的这些功能。
但真是所有的情况都是如此的嘛?
我们再看一个例子。比如blog和用户相关的业务。用户可以在blog登录、注销等,blog需要实时判断某一个用户是否登录等。登录和注销两个操作似乎可以通过类似account.XXX.com提供的login和logout这样的URL接口实现。但是每次页面浏览要判断用户是否已经登录了,出于安全性等多方面的考虑,就不好通过URL来提供这样的服务。
那看起来,我们在第七阶段提出的按业务切分的理想情况,在实施的时候,并不是那样的完美。在实际的运行中,耦合是不可避免的。
有了耦合,我的第一反应基本上就是看看是否能够借助设计模式来解决这些的问题。其实呢,设计模式早已经给我们比较好的解决方案(但绝对不是完美的解决方案。俗话说的:没有最好,只有更好!)。在这篇文章的最初已经提到过了,为了增强网站代码的可重用性,我们引入了一些框架,比如:struts、spring、hibernate等等。其实这些框架,基本上是围绕着MVC的原则来设计的。struts、webwork等框架,将视图和逻辑控制分离;spring负责组织业务逻辑的数据;hibernate很好的做了数据访问层的工作,实现了ORM。
那现在我们采用多机分布式的时候,是否可以借鉴这些思想呢?其实也是可以的。