从技术角度讲解网站是如何从小成长起来(8)
【第十三阶段:分布式计算和存储的运维设计与考虑】
以上的部分已经从前到后的将系统架构进行了描述,同时针对我们会遇到的问题进行了分析和处理,提出了一些解决方案,以保证我们的系统在不断增长的压力之下,如何的良好运转。
不过,我们很少描述运维相关的工作,以及设计如何和运维相关联。系统运维的成败,直接决定了系统设计的成败。所以系统的运维问题,是设计中必须考虑的问题。特别是当我们有成千上万的(tens of thousands)台机器的时候,运维越发显得重要。因此,在系统设计初期,就应当把运维问题纳入其中来进行综合的考虑。
如果我们用人来管机器,在几台、几十台机器的时候是比较可行的。出了问题,人直接上,搞定!不过,当我们有几百台、几千台、几万台、几十万台机器的时候,我们如果要让人去搞定,那就未见得可行了。
首先,人是不一定靠谱的。即使再聪明可靠的人,也有犯错误的时候。按照一定概率计算,如果我们机器数量变多,那么出错的绝对数量也是很大的。同时,人和人之间的协作也可能会出现问题。另外,每个人的素质也是不一样的。
其次,随着机器数量的膨胀,需要投入更多的人力来管理机器。人的精力是有限的,机器增多以后,需要增加人力来管理机器。这样的膨胀是难以承受的。
再次,人工恢复速度慢。如果出现了故障,人工来恢复的速度是比较慢的,一般至少是分钟级别。这对于要提供7×24小时的服务来说,系统稳定运行的指标是存在问题的。同时,随着机器的增多,机器出问题的概率一定的条件下,绝对数量会变多,这也导致我们的服务会经常处于出错的情况之下。
还有,如果涉及到多地机房,如何来管理还是一个比较麻烦的事情。
如果我们能转换思维,在设计系统的时候,如果能有一套自动化管理的模式,借助电脑的计算能力和运算速度,让机器来管理机器,那我们的工作就轻松了。
比如,我们可以设计一套系统,集成了健康检查、负载均衡、任务调度、自动数据切片、自动数据恢复等等功能,让这套系统来管理我们的程序,一旦出现问题,系统可以自动的发现有问题的机器,并自动修复或处理。
当然以上都是比较理想的情况。凡事没有绝对之说,只是需要尽可能达到一个平衡。
好了,说了这么多的问题,要表述的一点就是:人来管理机器是不靠谱的,我们需要尽量用机器来管理机器!
接下来,我们比较简单的描述一下一个比较理想的自动化管理模型。
我们将我们的系统层次进行初步的划分。

我们将系统粗略的划分为三个层次:访问接入层、逻辑处理层和数据存储层。上一次对下一层进行调用,获取数据,并返回。
因此,如果我们能够做到,说下一层提供给上一层足够可靠的服务,我们就可以简化我们的设计模型了。
好,那如果要提供足够可靠的服务,方便调用的话,应该如何来做呢?
我们可以针对每一层来看。
首先,看看访问接入层:
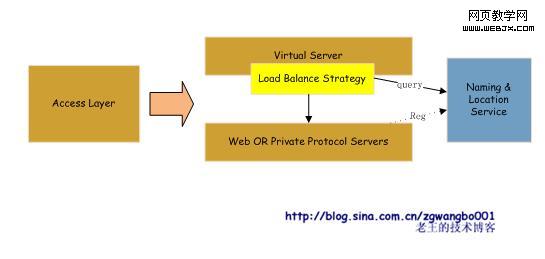
所有的Web Server和 Private Protocol Server将服务注册到命名和定位服务上。一旦注册后,NLS会定期去检查服务的存活,如果服务宕掉,会自动摘除,并发出报警信息,供运维人员查阅。等服务恢复后,再自动注册。
Virtual Server从NLS获取服务信息,并利用负载均衡策略去访问对应的后继服务。而对外,只看到有一台Virtual Server。
接下来,我们看看逻辑层:

由于HTTP的无状态性,我们将逻辑代码按标准接口写成一个个的逻辑处理单元,放入到我们的逻辑处理容器之中,进行统一的运行。并通过容器,到NLS中注册。Virtual Server通过NLS获取到对应的信息,并通过负载均衡策略将数据转发到下游。
这里比较关键的数据处理单元,实际就是我们要写的业务逻辑。业务逻辑的编写,我们需要严格按照容器提供的规范(如IDL的标准等),并从容器获取资源(如存储服务、日志服务等)。这样上线也变的简单,只需要将我们的处理单元发布到对应的容器目录下,容器就可以自动的加载服务,并在NLS上注册。如果某一个服务出现异常,就从NLS上将其摘掉。
容器做的工作就相对比较多。需要提供基本的服务注册功能、服务分发功能等。同时,还需要提供各种资源,如:存储服务资源(通过NLS、API等,提供存储层的访问接口)、日志服务资源等,给处理单元,让其能够方便的计算和处理。
总体来说,因为HTTP的无状态特性,以及不存在数据的存储,逻辑层要做到同构化是相对比较容易的,并且同构化以后的运维也就非常容易了。
最后,看看数据存储层。
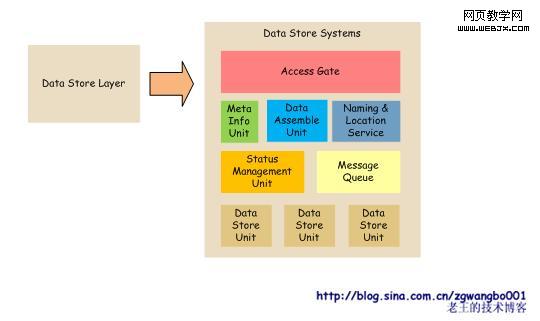
存储层是运维设计中最难的一部分。因为根据不同的业务需要,可能提供不同的存储引擎,而不同的存储引擎实现的机理和方式可能完全不一样。比如,为了保证数据的有效性和一致性,有些存储系统需要使用事务;而有些业务,可能为了追求高效,可能会牺牲一些数据的一致性,而提供快速的KV查询等等。
因此,数据存储层的异构性就是运维设计中亟待解决的问题。
一种比较理想的方式,就是让各个存储系统,隐藏内部的实现,对外提供简单的访问接口。而在系统内部,通过meta server、data assemble server、status manager、message queue等管理单元来管理数据存储单元。当然,这只是其中一种方式。也可以利用mysql类似的主从级联方式来管理,这种方式也是可行的。
数据存储系统的设计,也没有一个固定的规范(比如:Big Table、Cassandra、Oracle数据库集群等),所以运维的设计需要在系统中来充分考虑。上述图示只是提供了一种简单的设计方案。
好了,有了多个层次的详细分析以后,上一层次调用下一层次,就直接通过固定的地址进行访问即可。
不过有一个问题就是,如果我们的Virtual Server是一个单点,出现故障后,该层就不能提供服务。这个是我们不可接受的。怎么办呢?
要解决这样的问题,就是利用冗余。我们可以将我们的服务划分为多个组,分别由多个VS来管理。上层调用下层的时候,通过一定的选择策略来选择即可。这样,如果服务出现问题,我们就能通过冗余策略,将请求冗余到其他组上。
我们来看一个实例:
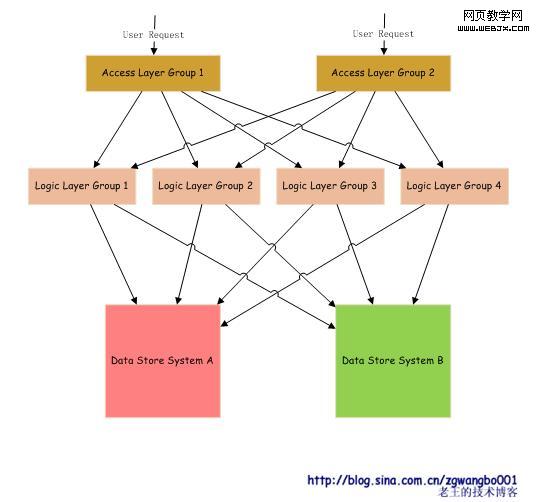
用户通过域名访问我们的服务,DNS通过访问IP解析,返回对应访问层的IP地址。访问层将请求转发到对应的逻辑处理组,逻辑处理组从不同的存储系统里获取数据,并返回处理结果。
通过以上的分析,我们通过原有的一些技术手段,可以做到比较好的自动化运维的方式。不过这种运维方式也不是完全智能的。有些时候也需要人工的参与。最难的一点就是存储系统的设计和实现。如果要完全的自动化的话,是一件比较难的事情。
说明:以上的描述是一个比较理想化的模型,要真正实现这种模型,需要很多的辅助手段,并且需要搭建很多基础设施。可能会遇到我们没有提到的很多的实际问题,比如:跨机房网络传输延迟、服务间隔离性、网卡带宽限制、服务的存活监控等等。因此,在具体实施的时候,需要仔细分析和考虑。