�Ӽ����ǶȽ�����վ����δ�С�ɳ�����(5)
����������һ�����ǵ�ҵ��
��ʵ���ǵ�ҵ������Է�Ϊ���ࣺ
һ����ʵ�ʵIJ�Ʒ��ص�ҵ���磺blog��news�ȵȡ���Щҵ��֮�����϶Ȳ��Ǻܸߣ���������ͨ���ṩHTTP�Ľӿڼ���ʵ��ҵ����Ҫ�Ļ�ͨ����ˣ�������������������ǿ��Ի�������ҵ��ֱ��ֵġ�
�������������磺�û��ʺŹ�������Ϣ֪ͨ�ȵȡ���Щ�������������ҵ����������������Ҫ�ṩ��ͨ�õġ�����ȫ�ġ����ȶ��Ľӿںͷ����ǣ����ڻ���ҵ�������ͻ��֣���û��һ���ض��Ĺ���ġ����磬imageͼƬ�������п��ܸտ�ʼ��һ��ҵ�����һ�����Ժ��ϵͳ��Ҫ������ǿ����������ȻҲ�ͳ�Ϊ��һ����������
���ԣ�����������������ǿ��Է��ַ�������ͣ������ǹ̶��ġ�Ҫ�ܺõĽ��������ϵ����⣬Ҳ��û��һ��ʮ�������Ľ�����������������ľ��Ǿ���������ϣ�ͨ��ij�ַ�ʽ���ܹ��ܺõĴﵽ��ϺͿ�ά���Ե�ƽ�⡣
�ܵ�������MVCģʽ��ʵ�������ṩ��һ���ȽϺõķ�����
���ǰ�ϵͳ������ά���Ͻ��л��֣���ֱ��ҵ��ˮƽ��������
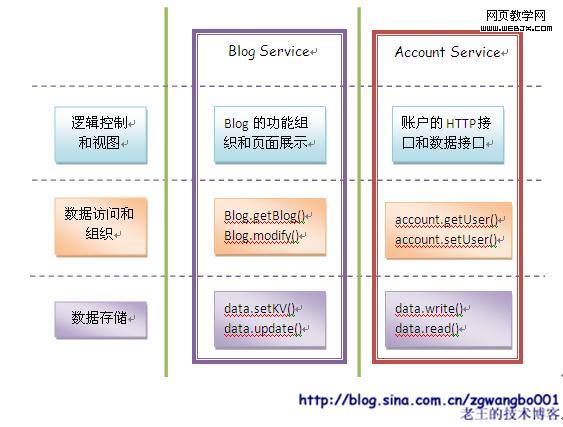
�������������Ļ����Ժ��ƺ�������û��ʵ���Եĸı䡣���ǣ����ǿ�����ȷ��������Ƶ�ԭ��ǿ���˴���Ŀɸ����ԡ����⣬��ؼ����ǣ�����֮�����������Ϲ�ϵ��������ȷ�ĵط�������ͬʱ�����ǻ����Խ�ҵ���ڲ��Ľṹ���в�֣����õ���ǿ���á�
���ݷ��ʺ���֯�㡢���ݴ洢�㣬������λ�����εIJ�Σ�Ӧ��������ϵͳ�ڲ��IJ�Σ�ԭ��������ò�Ҫ����Žӿڵģ�����ϵͳ�����Ͼͻ�dz��Ĵ��ҿ�ά���Ի�dz����ѡ��������ƺ���ͼ�㣬ʵ�������ṩ���⣨���û���������ϵͳ����õķ��ʵ���ڡ���Ȼ�������ڿ�����HTTPЭ��ģ�Ҳ�����Ƿ�HTTPЭ��ġ�
���磬����account�������ṩ����HTTPS���û����ŵ�login��logout����Ҳ�ṩ����XXX Protocol���ݽ�����Э��ĸ��ڲ���get_session���Ӽ������������ֻ�Ǹ��ݷ���ͬ���ṩ��ͬ�����ݽ�����ʽ���Լ���ͬ�İ�ȫ���ơ�����Ҳ�DZ�����һ�����ھ۵���ϵ�ԭ��
���ﻹ�м���������Ҫ������û����ϸ���ἰ��ϵͳ��������ݴ���Э�顢�ӿ�API��������ʶ�λ���⼸������ʵ���ϻ�����ά���������أ�����ŵ���������ϸ���ۡ�
����ʮ�Σ����ݴ洢�Ż���
��ǰ��Ľ��У����Ƕ�ʹ�����ݿ���ΪĬ�ϵĴ洢���棬����̸�۹��ڹ������ݴ洢�Ļ��⡣���ǣ����ݵĴ洢ȴ�����������ڶ������վ���ٵ�����ĵ����⡣�����ڶ������ͷ���Ƴ��Լ���“�߶�”�洢���棬Ҳ�������ڶ�������磺google��BigTable��facebook��cassandra���Լ���Դ��Hadoop�ȵȡ������ڶ�IT��ͷҲ���Ƴ��Լ���“��”�洢���档
��ʵ��Щ�洢�����õ�һЩ�ؼ�����������Ĺ��ԣ����磺Meta��Ϣ��������Ƭ�����౸�ݡ������Զ��ָ��ȡ���Ϊ֮ǰ��Ҳ����һЩ�������о������Dz����ر����룬�����ڴ�ָ�ֻ��š���̸���ۡ���ص��������ϱȱȽ��ǣ��������Ȥ��search�ɡ�^_^
��ϵ�����ݿⳣ�õ��м��������磺MySQL��PostgreSQL��SQLServer��DB2�ȣ���Ȼ����NB��Oracle��������ΪDB�ư�����Č�˿��û������������ʹ�ù������ĸ�˧�����ݿ⣬����������
������ʹ��Ƶ����ߵ�Ӧ��Ҫ����MySQL������Ҫ���ǿ�Դ����������ṩ��һЩ���ԣ����磺���ִ洢���桢����ͬ�����Ƶȣ�ʹ�������dz��ķ��㣻�ٴΣ�����һ�����ʣ�LAMP��������Ϊ���վ�ıر����������У��ϸ߷�����ȶ��ԡ�
��ϵ������ʹ�ý�����վ��ü������ɣ������Ǹ���վ������һ�����ݿ⡣����һ�£����û������ͨ�õĹ�ϵ�����ݿ⣬���ǵ����������ô���ģ�
��ϵ�����ݿ���95%�ij������ǹ����ķdz��õġ�����ֻҪ���õõ��������зֺ������ܹ���Ʒ���Ҫ���������Ǿ����ܹ�����ҵ����������ںܶ������վ�ĺ�̨�������������ݿ���Ϊ���Ĵ洢���档
���⣬������ıȽ��ȵ�һ���������NoSQL��˵��������ʵ���Ƿ�����ϵ�����ݿ�����������ԣ����磺��������ȵȡ�����ƣ������߸���ע�ڴ洢�������Ƚ������ģ����磺BDB��MongoDB��Redis�ȵȡ���Щ�洢�����ṩ��Ϊֱ�ӵ�Key-Value�洢�������㻥������Ч���ٵ�ҵ��������ʵ��������һ���Ƕ���������ϵ�����ݿ⣨����MySQL���������ʹ����ô��Ĺ�ϵ�����ݿ����ԣ�Ҳ���Լ�KVģʽ������Ч�ʡ�
��������Щʱ��Ϊ�˽�ʡ������Դ�������洢�����Ч�ʣ��Ͳ��ò��������ҵ����Ҫ��ר�ô洢���档��Щ�洢�����Ч�ʣ������Ϲ�ϵ���ݿ�Ч�ʸ�10��100�������磬��һ��ͼƬ���洢��ͼƬ����1�ڵ�10�ڣ�����100�ڣ��������е��������緢�������ﵽ10�ڻ���100�ڡ��������������������������ݿ����洢��Ȼ���ԣ������п�����Ҫ�ķ��൱��Ļ�������ά���ɱ��ʹ��۲�С��
��ʵ��������ͨ����ҵ�����Ƕ����ݵIJ����Ǿ����ĸ����顢�塢ɾ��������Ӧ���ݿ�IJ�������select��insert��delete��update�����Լ���ƵĴ洢�����Ǿ��Ƕ����ĸ������е�ij����������Ե��Ż��������м������ݲ�ͬ��ҵ���ص㣬ʹ���ĸ��ӵĸ�Ч�����磺���������ԣ����ܾ���Ҫ����Ͳ�ѯ���кܸߵ�Ч�ʣ���ɾ�����ĵ���������ô�ߡ����ʱ�Ϳ�������һ����ɾ�����ĵ����ܣ����ص���ڲ���Ͳ�ѯ�ϡ�
��ҵ���ϣ����ǵ��ύͨ�����Կ�����ijһ��ά����������ġ����磬ÿһ�������߲��Ϳ��ܶ�����һ��id����Щid�����ǰ������е���������ʱ������ȡ�����ѯ��ʱ�����ǰ�������һ��ά�ȵ�˳����֯�ģ����磺����ע������֯������Ϣ�������������һ����ͻ�������ύ����֯˳��Ͳ�ѯ����֯˳��һ�¡�
�����������ǵĴ��̡��������ڳ�����̻��ǻ�е��ʽ��ת�ģ�����Ƭ���д�ͷ�ȵȡ�����Ҫд����߶�ȡ��ʱ��ͷ��λ����ͬ����Ƭ�IJ�ͬ�����ϣ�Ȼ���ҵ����Ķ�Ӧ����Ϣ�������Ϣ��ɢ�ڲ�ͬ����Ƭ�������ϣ���ô��ͷѰ����ʱ��ͻ�Ƚϳ���
�����������������������ǵ�ҵ��ʹ��̵���֯��A��������ǰ���д������ķ�ʽ�洢���ݣ���ô���̻��Ժܸߵ�Ч�ʣ�������������д�뵽��Ƭ�У�������Ѱ������ô��ȡ��ʱ���ܾͻ���ְ��������ά������֯���ݣ��������п�����Ҫ�ڶ���ط�����ȡ���Ӷ�������Ǵ�������Ѱ����λ��ʹ�ò�ѯЧ�ʵ��¡�B��������ǰ���ijһ�ֲ�ѯά�����洢���ݣ���Ϊͬһҵ�������ж��ֲ�ѯģʽ�����Ƕ�ȡ��ʱ���ô���˳���ȡ���ɡ����������鷳���ǣ�д���ʱ���п�����Ҫ������Ѱ����λ�����ύ������һ����д�롣�����ͻ��д������鷳��
��ʵì�ܵ�������ǣ������Ĵ��̴洢��ʽ����������վ�����������ύ�Ͳ�ѯ������
�Ƿ��н�������أ��DZ����У�
Ҫ���������⣬���Դ����������֡�
1���ı����еĴ��̴洢��ʽ������Ӳ�����ٵķ�չ�����̱�����Ч�ʵõ��˼������������̵�ת�٣���Ƭ�ĸ����ȶ�������ӣ�����Ѱ�����ٶ������ܿ졣���ϻ���ȵļ�ǿ��Ч���������Ǻ����ԡ����⣬Flash Disk��Solid State Disk���¼��������룬�ı���ԭ���������ȡ�ĵ�Ч��û�����ݣ����ݾ��飬Flash��SSD��Ч�ʿ��Դﵽ10��100����ͨӲ�̵�������ʵ�Ч�ʣ���
2�����ݲ�ͬ��ҵ����Ч����֯���ݡ�����������û��д�������������������ƵĶ���������Ϊ��ȡҵ����֯��ά���ǰ��ˣ����ύ��֯��ά������ʱ�䡣���ԣ����ǿ��Խ�ij����һ��ʱ���ύ�����ݣ����ڴ�������кϲ���Ȼ����һ���Ե�ˢ�뵽����֮�С�������ij����һ��ʱ�䷢�������ݾ��ڴ����������洢������ȡ��ʱ��ԭ����Ҫ��ζ�ȡ�����ݣ����ڿ���һ���ԵĶ�ȡ������
��һ���ᵽ�Ķ�������Ҳ�Ŀ�ʼ�ռ�����ʵ�������ǵĸı��DZȽϴ�ġ����û�̫��ľ�����ʱ�䣬ȥ������ƺ��Ż�һ��ϵͳ����ֻ��Ҫ��һЩǮ����ʹ�����ܴ�����������������ijɱ����ڽ��͡�
���ǣ���Դ��Զ�Dz�����������ǰ�����ڴ滹��64K��ʱ�����dz�������ڴ��и�32M�ö���������ǣ��������ݵ����ͣ���ʹ����64G�ڴ棬Ҳ�ܿ�Ͳ����������ǵ�����
���ԣ���һЩ�����Ӧ�����棬���ǻ�����Ҫ����Ĺ�ע�ڶ����㡣
���ڴ洢�Ż���һֱ��һ���־õĻ��⣬Ҳ�кܶ����ķ���������������Ἰ���㡣